How to Achieve Sub-Second DDoS Mitigation for Production AI Environments
DDoS isn’t a “security problem.” It’s a latency and revenue problem AI leaders must own.
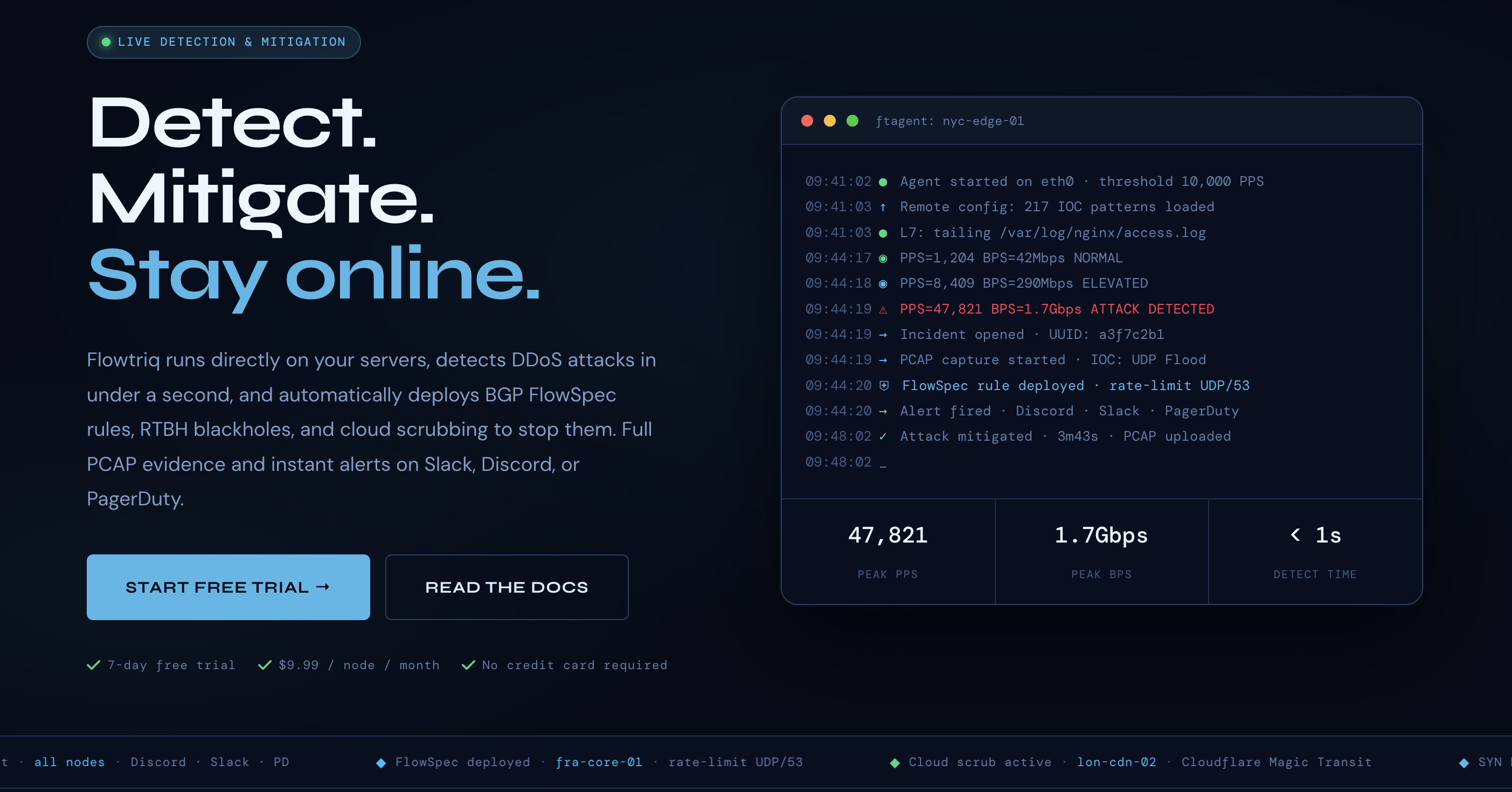
Most AI outages aren’t clever zero-days — they’re brute-force floods that choke inference APIs, blow SLOs, and trigger costly failovers. Flowtriq flips the script: a sub-second, agent-based DDoS detection and auto-mitigation layer that lives on your Linux servers, trims MTTD to under one second, and enforces runbooks without human-in-the-loop. Bottom line: if your models make money in real time, Flowtriq keeps revenue and reputation intact when the packet storms arrive.
The Business Case
Our team has seen AI platforms lose market share not from model quality, but from unpredictable downtime during high-visibility launches and adversarial spikes. Flowtriq matters because it’s built for production: a lightweight Python agent (ftagent) reads packets directly off NICs, learns normal baselines dynamically, and deploys BGP FlowSpec, RTBH, or cloud scrubbing in under a second — before customers notice. That speed compresses mean-time-to-detect and mean-time-to-mitigate from minutes to seconds, protecting SLOs for inference, fine-tuning endpoints, and data pipelines.
The flat $9.99/node/month pricing (or $7.99 annual) avoids the opaque, usage-based surprises typical of scrubbing-center contracts. For leaders managing volatile traffic — think model launches, viral demos, or seasonal e-commerce AI assistants — predictable costs with rapid, automated controls are a strategic edge. Flowtriq’s auto-PCAP capture on every incident, immutable audit logs, and new attack profiles give you the Experiment Logs needed for Failure Post-Mortems and compliance. Their Mirai botnet research (CVE-2024-45163) and “State of DDoS 2026” signals a credible, evolving threat intel posture you can operationalize today.
Key Strategic Benefits
-
Operational Efficiency:
- Sub-second anomaly detection and playbook-driven mitigations cut noisy war-room coordination during live attacks. Multi-channel alerts (Slack, PagerDuty, Discord, SMS, webhooks) fire in under a second, while auto-triggered PCAPs and IOCs fuel fast forensic cycles and cleaner Failure Post-Mortems.
-
Cost Impact:
- Flat per-node pricing eliminates surprise per-GB fees during volumetric events. By containing incidents quickly at the edge, you reduce autoscaling blowups, SLA credits, and overprovisioning buffers reserved “just in case.”
-
Scalability:
- Agent-based rollout across heterogeneous Linux fleets means you can protect inference nodes, fine-tuning boxes, and edge caches from a single dashboard. Dynamic baselines adapt to legitimate surges (e.g., a product launch) while escalation policies tap Cloudflare Magic Transit, OVH VAC, or Hetzner only as needed.
-
Risk Factors:
- Host-based agents require Linux kernel/NIC access and careful change control. Legitimate traffic spikes (marketing wins, model virality) can resemble floods; tuning escalation thresholds and rehearsing runbooks is essential. BGP FlowSpec/RTBH integrations demand router privileges and cross-team coordination.
Implementation Considerations
We’d treat deployment like an MLOps rollout: measurable, staged, and reversible. Day 0–1: define SLOs (MTTD <1s, MTTR <60s), choose escalation tiers (FlowSpec → RTBH → scrubbing), and map alert routes. Day 2–3: deploy ftagent to 10–20% of Linux edge nodes; integrate Slack/PagerDuty; connect to SIEM for immutable audit ingestion; enable status pages for stakeholder comms. Day 4–5: run synthetic floods in a canary segment; validate auto-PCAP capture, playbook sequencing, and rollback paths. Day 6–7: tune baselines and finalize runbooks; expand to remaining nodes.
Resource-wise, budget a small tiger team: 1–2 NetOps for BGP/RTBH, 1 SRE for rollout scripting, 1 SecOps for IOC libraries and incident response, and a product owner to align SLOs and customer comms. For enterprises (50+ nodes), request the custom IOC libraries and 365-day PCAP retention to strengthen your Experiment Logs and Fine-Tuning Guides for incident response. Integration is straightforward — Linux servers, Python agent, router access if using FlowSpec/RTBH, and optional connections to scrubbing providers.
Competitive Landscape
While Lorikeet Security excels at proactive offensive security — vulnerability management, attack surface enumeration, and exposure reduction — Flowtriq is better suited for live, sub-second DDoS defense at the network and application layers. If your priority is finding and fixing configuration and code weaknesses, Lorikeet provides broader coverage. If your risk is high-PPS floods hitting inference gateways or game servers, Flowtriq’s packet-level agent, dynamic baselines, and automated playbooks provide faster time-to-mitigation with lower operational overhead.
Compared to pure-play scrubbing centers and WAFs, Flowtriq’s edge-first model detects earlier, limits unnecessary diversion, and avoids per-traffic surcharges. We’ve heard from community operators that this reduces false escalations during launch spikes and simplifies Failure Post-Mortems thanks to the automatic PCAP and immutable audit trail.
Recommendation
Greenlight a 7-day pilot on 10–20% of edge inference nodes and any latency-critical gateways. Define success as MTTD <1s, MTTR <60s, zero customer-visible impact, and no surprise mitigation bills. Integrate alerts, enable runbooks, and simulate at least two attack types (SYN flood, UDP amplification). If results hold, contract for enterprise features (custom IOCs, 365-day PCAP), integrate with your SIEM, and institutionalize post-incident Experiment Logs to convert every mitigation into a Breakthrough Story your teams can reuse. For proactive exposure management, pair with Lorikeet Security.